The aim of the AUS Lab I and Aus Lab II is to develop novel methods for complex problems for autonomous driving. The required working hours are 120. The projects are supervised by professors and/or PhD candidates.
At the end, a project report should be written, and a final workshop will be organized in which each participant will present their work in 10 minutes. The grade is given in the last week of the exam’s period.
For complex problems, the laboratory work can be continued as an MSc thesis.
A very important remark is that generative artificial intelligence (ChatGPT, Gemini, etc.) can be used but you must mark in the report how you did use it.
We offer the students several topics, but own ideas can also be implemented.
Topics in the fall semester of 2026
Underwater Motion Analysis and Reconstruction of Competitive Swimmers
We are looking for a motivated student to join a research project focused on the computer-vision-based analysis of underwater videos of competitive swimmers. The aim of the project is to extract precise, quantitative motion information from real-world underwater recordings captured in challenging visual conditions.
The project focuses on measuring and reconstructing key biomechanical and kinematic properties of swimmers, including body posture (positions and joint angles), swimming dynamics such as velocities and stroke frequencies, trajectories of individual body parts, and both instantaneous and time-averaged motion descriptors. These measurements enable a detailed, objective analysis of swimming technique and performance.
From a technical perspective, the work combines computer vision, image and signal processing, and applied geometry. Core tasks include robust detection and segmentation of the swimmer’s body under water, handling visual artifacts such as bubbles and surface reflections, tracking body parts over time, estimating motion trajectories, and extracting physically meaningful signals from complex measurements.
The project is strongly hands-on and data-driven. The student will work with real underwater video data, develop and test algorithms in Python, and create visualizations that support both scientific analysis and feedback for athletes and coaches. The work addresses open research problems and offers the opportunity to contribute to publications or thesis work.
Image Rectification for Stereo Vision
Image rectification is a transformation process used to simplify the correspondence problem in stereo vision. When two cameras are mounted on a platform like the ELTECart, they are rarely perfectly aligned; slight rotations or vertical offsets mean that a point in the 3D world will appear at different vertical coordinates in each image. Rectification mathematically projects both images onto a common image plane such that all corresponding “epipolar lines” become horizontal and perfectly aligned. This ensures that for any pixel in the left image, the matching pixel in the right image is guaranteed to lie on the exact same horizontal row (scanline), effectively reducing a 2D search space to a 1D search.
In a practical laboratory setting, this process relies on accurate extrinsic and intrinsic camera calibration. Students must first determine the relative rotation R and translation t between the two ELTECart cameras using a calibration pattern. Using these parameters, a rectification transform is computed to warp the raw, distorted images into a corrected pair.
A fully automatic software should be developed by the student that estimates the rectifying transformations based on chessboard images. Then another software should be developed that rectifies the recorded images sequences for the stereo setup of ELTECar.

Dense Stereo Matching and Disparity Estimation
Once the ELTECart’s stereo images are rectified, the next challenge is dense matching, the process of finding a corresponding pixel in the right image for every single pixel in the left image. Unlike “sparse” matching, which only tracks distinct features like corners or edges, dense matching aims to produce a full disparity map. Students will implement or utilize algorithms—ranging from local block-matching techniques to global optimization methods like Semi-Global Matching (SGM)—to compute the horizontal shift (disparity) between corresponding points. This requires balancing matching accuracy against computational cost, as the algorithm must handle difficult scenarios such as textureless surfaces (like a smooth floor), repetitive patterns, and occlusions where a point is visible to only one camera.
The output of this task is a dense disparity map, where the intensity of each pixel represents the distance shift between the two views. Because the cameras are rectified, this disparity is inversely proportional to the actual depth of objects in the scene. By leveraging the known baseline and focal length of the ELTECart’s sensors, students will transform this disparity map into a 3D point cloud. This allows the vehicle to perceive the world in three dimensions, enabling downstream tasks like obstacle detection, path planning, and environment reconstruction.
Machine learning is also very efficient for dense reconstruction, the student should compare the implemented methods to state-of-the-art pre-trained neural networks.
Topics supervised by Tekla Tóth (click on the link)
Ellipse Fitting on RGB camera images
For vehicles, the orientation of the wheels with respect to the car body determines the steering of the car. The goal of the project is to develop robust and rapid ellipse fitting algorithms. If the contour of the wheel is detected, the 3D location and orientation should also be computed. It is a very complex problem, it can be the basis for an MSc thesis.
For ellipse fitting, the key problems are
- Contour point detection
- Due to occlusions, only part of the contour is visible
- Robust estimation is a requirement
- Speed is also a key issue
- GPU-powered implementation is an option
Human Detection and Localization using Ground-based Microphone Array
Project Definition : Objective: Develop a system to detect human intruders in designated private zones using audio-based technologies.
Approach: Detection: Utilize a microphone array or multiple arrays to capture audio signatures specific to human walking patterns. The primary goal is to classify these patterns effectively to distinguish human presence from other sounds in the environment. Localization: Implement triangulation techniques to ascertain the position of the detected human within the private zone. Initially, the system will focus on localizing one object at a time.
Simulation and Development: Before deploying actual hardware, the system will be simulated using online tools and available datasets. This phase aims to refine the classification and localization algorithms under controlled conditions.
Field Testing: Upon successful simulation, the project will progress to field testing with hardware provided by the university. This phase will test the system’s efficacy in real-world scenarios and gather data to further improve its accuracy and reliability.
Industrial project: gaze estimation for chess players
A unique opportunity: work on an exciting research project in collaboration with one of the world’s most renowned living chess legends.
The task is to analyze videos of chess players streaming on YouTube, where the board with the mouse cursor, the head, the face, and the eyes are visible simultaneously, in order to extract patterns of eye movement. The research aims to determine when the player’s gaze is directed exactly to the point indicated by the mouse, and when it is not.
This requires:
1. synchronized analysis of mouse cursor, head, face, and eye movements,
2. 3D reconstruction of the playing environment and the player, using only the limited information available from raw YouTube videos.
During the research, it is required to cover both classical and deep learning based computer vision and 3D reconstruction methods
Data visualization and simulation software for testing calibration algorithms
The goal of the lab work is to create a data visualization and data simulation software that provides an easy way to test and develop the calibration algorithms of the GCVG research group. The application should be developed in Unity.
Basic Task:
The application should be capable of simulating 2D/3D LiDAR and camera systems, allowing users to set their relative positions in space and intrinsic parameters. In addition to sensor simulation, the program should also be able to place simple target objects commonly used in calibration algorithms, such as planes, chessboards, cylinders, and spheres. The program should provide options for texturing objects and loading more complex meshes. The application should also allow the saving of simulated sensor data.
In addition to simulation, the developed application must be able to simultaneously read and display LiDAR point clouds from various file formats (.PLY, .PCD, .XYZ) and camera images. The program should provide the capability to specify the intrinsic and extrinsic parameters of the sensors and use these to color the LiDAR point cloud based on the images, as well as display the points of the point cloud on the images.
Bonus:
The application should provide the ability to easily integrate calibration algorithms using the aforementioned data through interfaces or abstract class implementations. The program should give users implementing the algorithm access to the data, as well as the external and internal parameters of the sensors (if available). The program should be able to run correctly implemented algorithms and display and evaluate the results returned by the algorithms. For ease of implementation, this could be a separate application or library.
Monocular depth estimation by a pre-trained network
The goal of this project is to apply a pre-trained network, for example ‘Depth Anything’ for the images of ELTECar.
The results of DepthAnything are very spectacular, however, the depth values are not always correct. Moreover, the obtained depth is defined up to an unknown scale.
The aim for this semester is to define the scale between estimated and real depth maps based on LiDAR measurements and/or stereo vision /planar omnidirectional vision.
Visualization of data recorded by ELTECar data
ELTECar is the vehicle of the Faculty of Informatics, mounted with several different sensors:
- Digital cameras with normal and fisheye lenses
- 3D Lidar
- GPS device with RTK correction, reaching at most 3cm precision for localization
- IMU: accelerometer, magnetometer
The aim of the project is to generate videos that can visualize different sensor data as spectacularly as possible.
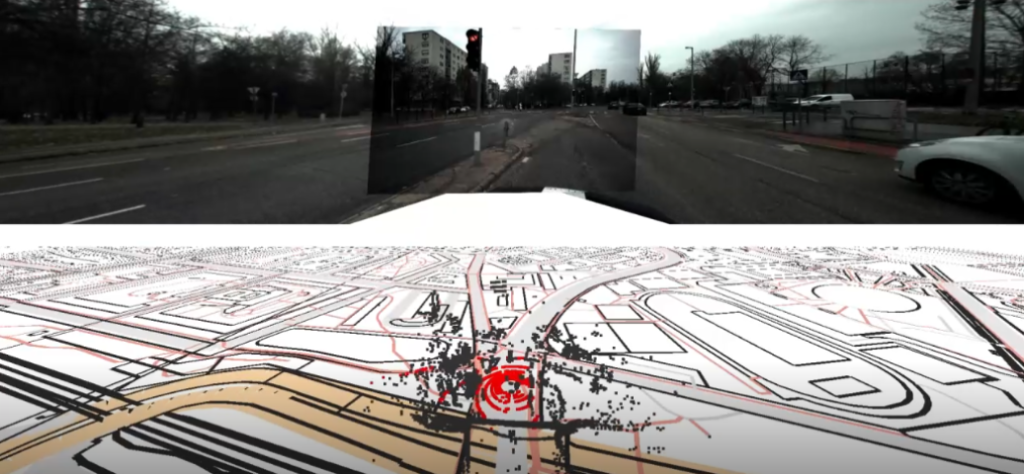
Example visualization. Top: four cameras stitched to each other. Bottom: LiDAR points drawn to OpenStreetMap, ground points visualized by red.
3D Vision via Affine transformations
The application of affine correspondences is beneficial over simple point correspondences in 3D vision because they capture more information about the local geometric transformation between images. While a simple point correspondence only matches the location (x,y) of a feature, an affine correspondence also matches the shape of the local neighborhood around that feature, effectively describing how a small circular region in one image is transformed into an ellipse in the other. This captures local rotation, scaling, and shear. This richer information provides more powerful constraints for solving 3D vision problems. It leads to more robust and accurate estimations, especially when dealing with significant changes in viewpoint where the apparent shape of objects is distorted.
Affine correspondences can be exploited for several 3D vision problems, like
- Image stitching/homography estimation
- Fudamental/essential matrix estimation
- Relative pose estimation
- Surface normal estimation.
All the methods are very sensitive to the quality of the affine transformations, retrieved from image pairs. The aim of the project is to compare different techniques and method both classical image processing ones and neural networks, in order to find the most accurate.
If the student is open to do research work, development of new solvers is also an option. In that case, after successful research, publication on international conferences/journals together with the supervisor is welcome and encouraged.